

Deep Learning for Face Anti-Spoofing: A Survey

저자: Zitong Yu, Yunxiao Qin, Xiaobai Li, Chenxu Zhao, Zhen Lei, Guoying Zhao
요약: Face Anti Spoofing(FAS, 안면 위변조탐지) 서베이 논문
Github: https://github.com/ZitongYu/DeepFAS?tab=readme-ov-file
Paper(arxiv): https://arxiv.org/abs/2106.14948
Conference:
Abstract & Introduction
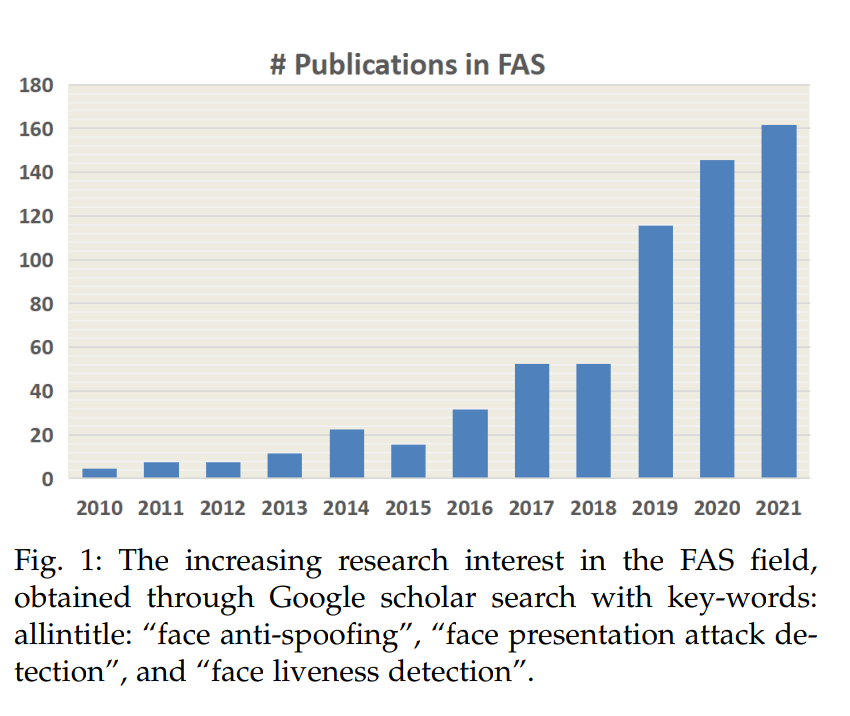
편리하고, 주목할만한 정확도로 인해 안면인증 기술은 모바일 결제의 체크인 수단 등으로 많이 적용되어 왔다. 하지만, 현존하는 안면인증 시스템은 print, replay, makeup, 3d-mask 등이 포함되는 presentation attacks (PAs)에 취약하다. 그러므로, 학교와 산업 둘다 안면인증 시스템의 보안을 위해 안면 위변조 기술을 개발하는 것에 주목하고 있다. 그림 1과 같이 점점 추이가 증가하는 모습을 알 수 있다.
예전에는 handcrafted 특징들 기반 방법론들이 제안되었다. 대부분의 전통적인 알고리즘은 풍부한 사전 지식이 필요한, 사람의 liveness 단서들과, handcrafted 특징들을 기반으로 설계되어 왔다. liveness cues, eye-blinking, face movement, head movement (nooding, smiling), gaze tracking, physiological signals (rPPG) 들을 기반으로 하는 방법들은 동적 차별성을 통해 확장되어 왔다. 하지만, 이러한 물리적인 방법들은 안면 비디오를 긴 시간동안 캡처하기 때문에 불편함을 준다. 더욱이, liveness cues들은 동영상 공격들에 의해 쉽게 혼합된다. 반면에, 고전적인 handcrafted 묘사들 (LBP, SIFT, SURF, HOG, DoG)들은 효과적인 spoofing 패턴을 다양한 색 공간(RGB, HSV, YCbCr)으로부터 추출하기 위해 설계되었다.
그 후, 몇몇 하이브리드 방식(handcrafted + deep learning), end-to-end 딥러닝 기반 방법들이 정적, 동적 안면 PAD를 위해 제안되었다. 대부분의 연구들은 FAS를 binary classification 문제로 다루었고, 간단한 binary cross-entropy loss를 사용하였다. 다른 binary vision tasks들과 다르게, FAS는 공격 방어의 입장과 같이 스스로 진화하는 문제이며 더 해결하기 어려운 문제다. 더욱이 일반적인 binary vision task는 명확한 semantic-cues(hairstyle, wearing, facial shape) 등이 있는 반면에, FAS에서는 재질, 기하학적 특징들을 주로 다루고, 이는 안면의 특징과 전혀 관련이 없으며 이러한 미세한 부분은 사람의 눈으로도 구분하기 힘든 점이 있다. 그래서, 합성곱 신경망(CNN)과 binary loss는 합리적으로 일반적인 binary vision task에서 다루는 semantic features와는 다른, screen bazel같이 unfaithful clues를 다룬다. 다행히도, 이러한 본질적인 단서 들은 몇몇 부가적인 위치 기반 방법론들과 밀접하게 관련이 있다. 예를 들어, print / replay / mask attacks 들은 geometric depth가 제한되고, 반사광에 대한 표현도 비정상적이다. 이러한 물리적인 증거를 기반으로, 최근에는 pixel-wise supervision 연구들이 주목을 받고 있는데, 이 방식은 더 세밀한 context-aware supervision signals들을 제공하고, 딥러닝 모델이 본질적인 위변조 단서들 학습하는데, 도움이 된다. 한편으로는, pseudo depth labels, reflection maps, binary label mask, 3D point cloud maps 들은 일반적으로 pixel-wise auxiliary supervisions 이며, 이것들은 스푸핑 단서들을 pixel, patch 단계에서 묘사한다. 몇몇 생성형 모델을 통해 본질적인 스푸핑 패턴을 reconstruction하는 연구도 있다. 주목할 점은 데이터에 의한 기존 방식들은 binary loss를 이용한 supervised 방식이다.
거대 규모 데이터 셋을 이용하여, 풍부한 공격 정보를 학습하는 연구도 증가하고 있다. 데이터 셋의 예로, CelebA-Spoof 데이터 셋은 10177 subjet, 156384 bonafide, 469153 spoof 이미지로 구성되었다. 몇몇 데이터는 어려운 케이스의 공격 데이터를 풍부하게 포함한다. 모달리티 측면에서 RGB 카메라 이외의 다양한 멀티모달을 기반 방식들도 있다. 예를들어, CASIA-SURF, WMCA는 RGB, depth, NIR 정보를 활용하여 효과적인 PAD 성능을 보여줬다. 이전 대부분 방식은 RGB만 사용했다.
평가관점에서 intra-dataset intra-type, cross-dataset intra-type 두 관점이 이전 FAS에서 넓게 사용되던 프로토콜이다. FAS는 실제로 open-set 문제로, 학습과 테스트 사이에 차이가 존재한다. 하지만 이전에는 이러한 문제를 고려한 연구가 없고, 대부분 미리 사전 정의한 학습데이터, 평가데이터에서 평가한다. 이렇게 학습된 모델은 쉽게 overfit되는 문제가 있다.
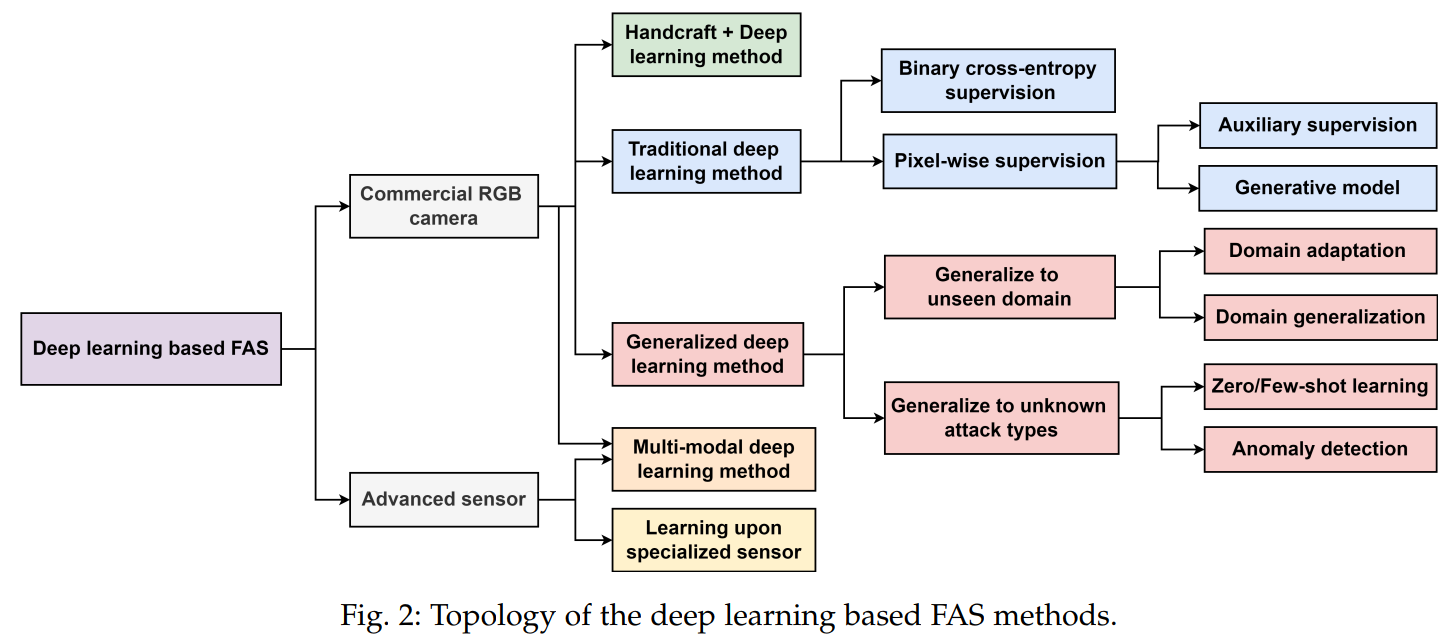
본 논문에서는, 미래의 연구를 시각화하기 위해, 가장 먼저 딥러닝 기반 FAS 최근 연구들을 포괄적으로 리뷰할 것이다. 소개하는 연구에는 몇몇 새롭고 영감을 주는 요소들이 있는데, 1) binary label (0 bonafide, 1 pa), pixel-wise supervision(depth map, …), 2) 전통적인 intra-datasets에 더해 우리는 domain 일반화를 위한 최신 방법론들을 수집하고 분석할 것이며, 3) RGB 카메라 기반과 다양한 멀티모달 기술을 소개할 것이다.
Background
Face Spoofing Attacks


Attacks on automatic face recognition (AFR) 시스템은 보통 두 개의 카테고리로 나뉜다. 1) parallel fusion, 2) serial scheme.
안면 공격유형은 1) impersonation, 특징등을 이용해 누군가로 인지되는 유형, 2) obfuscation 공격자의 identity를 숨기는 유형이 있다. Geometry 특징에 따라 2D, 3D로 구분할 수 있고, print, video, flat, wrapped, eye-cut, mouth-cut 사진 등이 있다. 3D 공격에는 3D 마스크를 통한 공격이 있다. 2D와 비교해서, 색, 질감, 기하학적 구조에서 더 현실적이다. 마스크 또한 재질에 따라 다양한 유형으로 나누어진다. 또한 공격유형을 전체, 부분 공격으로 나눌 수있다.
Datasets for Face Anti-Spoofing & Evaluation Metrics / Protocols
안면 위변조 탐지를 위한 다양한 데이터 셋이 존재하며, 평가방법 또한 다양하다. False Rejection Rate(FRR), False Acceptance Rate(FAR)을 많이 사용. EER과 AUC도 함께 사용된다. 최근에는 용어를 바꿔서 APCER, BPCER, ACER라고 부르며 평가를 하기도 한다.
평가 절차는 크게 아래와 같이 4개로 나눌 수 있다.
1) intra dataset, intra type
넓게 사용되는 방법. 동일한 도메인의 데이터셋에서 학습/평가 데이터 셋 구축. OULU-NPU datasets이 대표적
2) cross-datasets intra type
도메인 일반화 목적. 학습 테스트 도메인의 유사도가 매우 낮음. 보지 않은 도메인을 위함.
3) intra-datasets cross-type
도메인을 비슷하거나 동일하지만, 학습 평가과정에서 공격 유형이 서로 다름
4) cross-datasets, cross type
서로다른 도메인, 서로 다른 공격유형
Deep Fas with Commercial RGB Camera
하이브리드 (handcrafted + deep learning model)
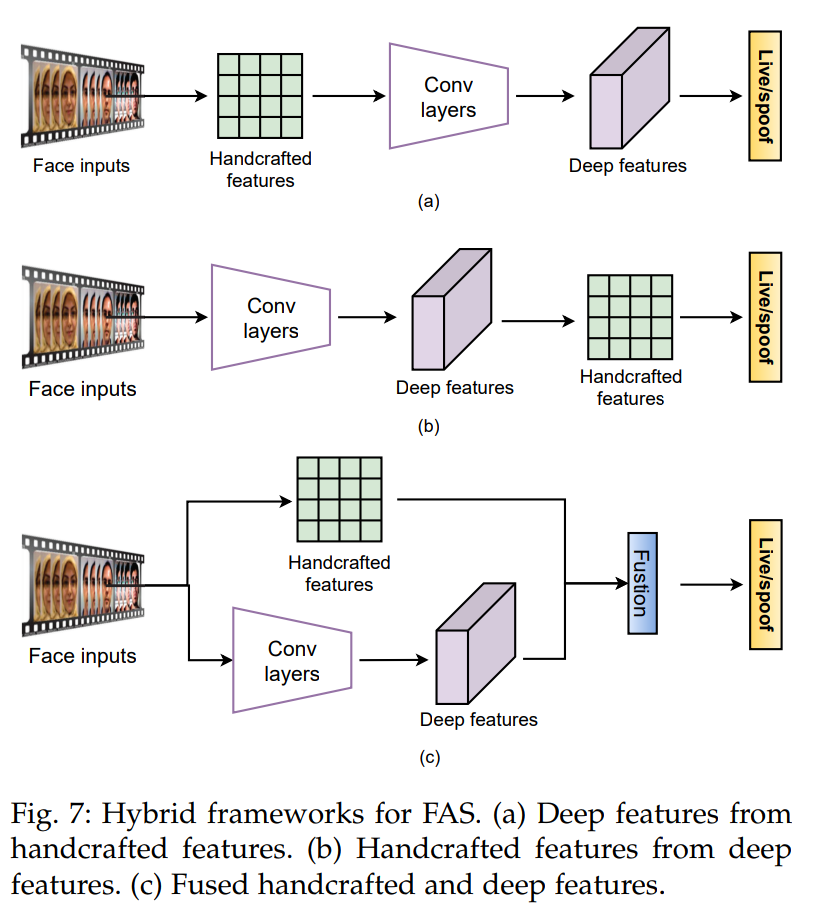
handcrafted 방식은 pixel 단계의 정보를 잃어버리기 때문에 성능에 제한이 생긴다. 이를 해결하기 위해, VGG 모델로 특징추출하고, PCA 기반 특징 추출 LBP 방식이 있는데, handcrafted features들이 conv모델에 너무 의존적이고, 얕은것이 좋은지 깊은것이 좋은지 알려지지 않은 단점이 있다. 두 방식을 따로 학습하는 방법도 있는데, 이 방법은 optimal score weights를 어떻게 결정하는지가 어렵다.
HOG, LBP maps 사용하는 등 handcrafted 방식으로 더 깊게 접근할 수 있는데, 이러한 방식은 non-texture clues (rPPG, motion blur 등) 잘 잡고 표현을 잘 학습한다. 하지만, handcrafted features는 전문적인 지식과 관련되어 있고, 학습이 불가능하다.
또한, handcrafted feature, deep feature 둘 사이의 차이와 양립할 수 없는 문제가 있으며, 이는 성능 저하로 직결된다.
Traditional deep learning method
학습 가능한 파라미터, 안면 입력을 스푸프 탐지에 매핑하는 함수를 직접적으로 학습한다.
direct supervision with binary cross-entropy loss, pixel-wise supervision with auxiliary tasks, generative models 등을 포함한다.
Direct supervision with binary cross entropy loss
직접적으로 binary 분류를 통해 entropy loss를 사용할 수 있다. 모델 연구도 진행, CNN은 학습 잘 되지만 쉽게 overfit 되는데, 이를 해결하기 위해 사전학습 모델을 활용한 모델 구조 등장하였고, 모바일 레벨에서는 mobilenet-v2 같은 경량화 모델 등장. 여기서 언급된 것들은 High-Level의 의미론적 표현에 초점을 맞추고, Low-Level(낮은 레벨)의 특징을 무시하는 경향이 있는데, 낮은 레벨의 특징은 스푸핑 패턴과 관련이 높다. 이를 해결하기 위해 FCN, LSTM 등 다양한 모델 구조를 활용하는 연구 등장하였다.
Binary cross entropy loss의 intra, inter 취약 문제를 해결하기위해 재질이나 스푸핑타입을 기준으로 다중 분류를 하는 연구도 있다. 하지만 이러한 경우 hard negative 케이스에 대해 활용하기가 어렵다. 한가지 경우로 작은 intra 클래스 거리와 먼 inter 클래스 거리의 세밀한 부분을 학습하기 위해 tiplet, angular margin 사용한 경우도 있다. 하지만, 여러 재질의 특성상 정상 비정상의 분포가 불균형한 경우가 많다. 다른 방향으로, 하드 샘플에 대한 충실한 성능을 위해 focal loss를 사용하는 경우도 있다. 전체적으로 바이너리 로스는 사용하기 쉽고 빠르게 수렴한다. 하지만, 이러한 방식은 글로벌 정보 (공간적) 정보만을 제공하기 때문에 패턴들에 쉽게 오버핏된다. 더욱이 FAS모델들은 블랙박스 구조여서 이해하기 힘들다.
Pixel-wise Supervision
이미지를 직접적으로 이중 분류하는 것은 스크린 베젤같이 불공정한 패턴을 쉽게 할습할 수 있다. 대조적으로, 픽셀 기반 지도학습은 보다 본질적인 특징을 학습하기 위해, 더 세밀하고 의미론적으로 관련있는 실마리를 학습한다. 그 중 하나로, sudo depth label, binary mask label, reflection maps 등의 물리적 실마리와 차별적인 디자인등의 부가작 작업들로 라이브, 스푸프를 구분하는 단서로 묘사한다. 반면에, 생성형 모델들은 최근 일반적인 스푸프 패턴 추정을 위해 활용되고 있다.
Pixel-wise supervision with auxiliary task
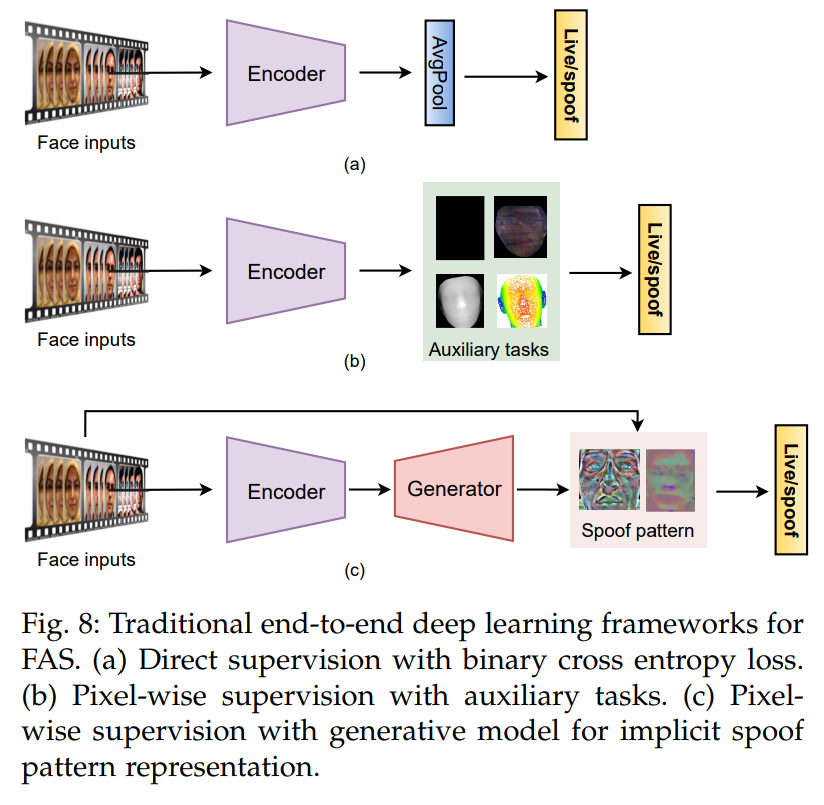
대부분의 FAS 공격중 하나인 종이 공격은 뎁스가 없고, 이러한 차별점을 이용하여 pseudo depth label 을 이용하여 뎁스를 예측하고, 이를 통해 위변조를 탐지하는 연구가 있다. DepthNet holistic depth maps를 예측할 수 있다. 그 중 하나인 FAS-SGTD는 클래식하고 장단기 모션을 예측하여 안면 뎁스를 예측하는데 훌륭하다고 알려져있다. 매번 3D 모양의 라벨을 만드는 것은 많은 자원이 필요하며 비효율적이다. 이와는 다르게, binary mask label은 만들기 쉽고 더 일반화할 수 있다. 이러한 마스크를 통해, 우리는 Print Attach이 상응하는 패치에서 발생하는지 아닌지 알 수 있고, 이는 공격 유형에 구애받지 않고 공간적으로 해석이 가능하다.
스푸핑에 대한 미세한 실마리는 보통 서로다른 공간에 각각 존재하는데, 기존 바닐라 방식의 학습방법은 모든 패치를 동등한 기여도로 다루는데, 이러한 방식은 특징 표현의 편향을 야기할 수 있다. 이를 해결하기 위해 binary loss를 계산하기 전에 학습 가능한 attention 모듈을 추가하였다. 현재는 유연하고 쉽게하기 위해, 라이브 / 스푸프 분포가 동일한 안면 영역을 가진다고 가정하고, 0과 1로만 구분한다. 하지만 ,이는 노이즈에 매우 취약한 단점이 있다. (FunnyEyE)
전체적으로 pixel-wise auxiliary supervision 방식은 물리적으로 의미와 설명가능한 라이브 위변조 특징을 학습할 수 있다. 게다가 다양한 요소들과 함께 일반화된 FAS 모델을 학습할 수 있는 실현 가능성을 보여준다. 하지만 이러한 장점과는 반대로 두 가지 큰 제약점이 존재한다. 1) 픽셀 기반 방식은 퀄리티(해상도)에 매우 의존적인데, 낮은 퀄리티와 노이즈가 있으면 성능이 매우 저하된다. 2) 사람의 손에 의해 설계된 라벨 혹은 생성된 라벨에 대한 신뢰도가 떨어진다.
pixel-wise supervision with generative model
최근에는 스푸핑패턴을 직관적으로 추출하는 생성형 모델이 주목받고 있는데 그 중 하나로, auto encoder를 이용하여 패턴을 이해하는 연구가 있다. 이와는 다르게 reconstruction error maps를 이용하여 라이브 데이터를 학습하여 위변조 탐지 연구도 진행되고 있다. 하지만 낮은 퀄리티의 생성 결과물은 노이즈를 만들 것이고, 이는 성능 저하를 발생시킬 것이다. 픽셀 기반 생성형 모델은 전문적인 설계 방식을 조금 더 유연하게 해주며, 예측된 스푸핑 패턴들은 시각적으로도 설명이 가능하고 사람의 지식으로 묘사하는 것에 도전하고 있다. 하지만, 가벼운 픽셀 기반 지도는 쉽게 로컬 최적화에 빠질 수 있고, 과적합 상태가 될 수 있다.
Generalized Deep Learning Method

전통적인 end-to-end 딥러닝 기반 FAS 방법들은 보지 않은 도메인에 매우 취약하다. 이러한 문제를 해결하기 위한 연구는, 1) domain adaption, generalization 기술과 2) zero/few-shot learning anomaly detection 기술이 연구되고 있다. 외부 환경에 따른 도메인의 변화, 새로운 공격 유형 등이 있다.
Generalization to Unseen Domain
도메인 이동이 있을 수 있고, 이는 성능 저하로 이어진다. 도메인 어댑션 기술은 타겟 도메인의 정보를 이용하여 간극을 줄이는 방법이다. 이와는 반대로, 도메인 일반화는 타겟 데이터에 대한 접근 없이, 다양한 소스의 도메인으로부터 정보를 학습하여 일반화된 모델을 만드는 것이다.
Domain Adaption
몇몇 연구에서는 semi-supervised learning 방식을 통해 도메인의 불변하는 특징 공간을 학스ㅂ하려고 한다. 하지만 이러한 세미 지도학습 방법들은 클래스 라벨의 밸런스에 매우 민감하고, 라벨링된 스푸프 샘플을 사용하지 못하는 경우 성능이 매우 저하된다. 또한 final classifier layer를 이용한 연구 방법과, kd 방식도 많은 연구가 진행되고 있다. kd 는 자식 모델의 수용량이 약하다는 단점이 있다. 도메인 어댑션이 타겟 도메인과의 차이를 줄여준다 해도, 실제 시나리오늘 가정했을때, 알려지지 않은 공격유형을 수집하는 것은 매우 어렵다.
Domain Generalization
도메인 일반화는, 다양한 도메인에서 특징들의 공통 구간이 있고, 알려지지 않은 타깃 도메인과 관련이 있다고 가정하고, 해당 공간을 학습한 모델은 알려지지 않은 도메인에 대해 일반화가 잘 될것이라는 연구다. 도메인과는 관련이 없는 특징을 학습하여 일반화된 특징 공간 학습하는 것이 목표다. 이러한 방법에는 크게 두가지 제약이 있는데, 1) 도메인에서 독립적인 특징들은 여전히 스푸핑과 관련 없는 데이터(아이디 또는 노이즈)를 포함할 수 있다. 2) 도메인 일반화된 특징들이 여전히 unsatisfactory 하다. 첫번째 문제를 해결하기 위해 disentangle generalized FAS features를 제안하는 연구도 있다. 하지만, 메타러닝 도메인 라벨이 필요한데 실제 환경에서는 없는 경우가 더 많다.
Generalization to Unknown attack types
대부분의 딥러닝 모델의 학습 및 평가는 클로즈드 데이터셋 기준으로 진행되는데, 이러한 경우 쉽게 과적합이 되며, 실제 환경에서는 성능이 낮다. 이러한 문제를 해결하기위해 few/zero shot learning 방식 혹은 one classification 방식의 연구가 진행되고 있다.
zero/few shot learning
가장 좋은 방법은 새로운 공격타입이 생길 때 마다 다시 학습 시키는것인데, 이러한 경우 리소스가 많이 들고 현실적으로 불가능하다. 이러한 문제를 해결하기 위한 방법 중 하나인 zero shot 방식은 일반화 모델을 사전학습 하며 보지않은 공격유형에 대해 탐지하는 방법이고, few shot 방식은 fine tuning 과정을 통해 모델을 학습하는 것이다. DTN 같이 트리를 이용한 방식과 메타러닝을 이용한 다양한 연구가 진행되었지만 여전히 문제는 존재한다. few shot 학습을 위해 새로운 공격 유형의 데이터를 도메인 적용에 사용하지 못하는 경우 혹은 매우 어려운 유형의 e.g., transparent mask, funny eye, and makeup 같은 공격들이다. Svm, gmm 방식을 시작으로 다양한 이상감지 연구 진행 중이며, one class classificatin(OCC) 분야로도 연구 활발하게 진행되고 있다.
Conclusion
최근에는 센서 등 멀티모달 연구도 진행되었으며, 미래에는 개인정보 이슈로 연합학습 활용 등 다양한 변화가 있을거라 예상한다.
'딥러닝 논문 리뷰 > Computer Vision' 카테고리의 다른 글
| [논문리뷰] SupCon: Supervised Contrastive Learning (0) | 2023.10.25 |
|---|